Reverse engineering Asustor's NAS firmware (part 1)
By Ricardo
Note: this was previously called “Running my NAS OS on a VM (part 1)” but I believe the new title is better.
I’ve been wondering for a while now if it would be possible to extract the OS from the NAS itself or a firmware image and boot it up on a VM. This would change a lot in terms of reverse engineering effort as we could even crash the kernel and it would not impact on my production systems. You see, people use Plex here at home, and it runs on my NAS: if it goes down, people are sad. It would also open possibilities of mass-building applications and libraries on the OS itself, which would reduce library compatibility issues - Entware’s GCC wouldn’t even run on the NAS, for example.
So, I decided to check if it’s possible.
Warning: this research was done during the course of many, many days. This is not a tutorial, but the story of it all went down. This is why sometimes it might sound weird why I’m returning to check something I checked a few lines before: a few lines before sometimes means the whole next week!
Getting the firmware image
I just got a copy of the firmware update image. Yup, that easy.
The file is called X64_G3_3.5.4.RE11.img and the URL can be easily found by checking the web interface requests. I’m not even joking:

So first thing we need to do is to figure out what exactly is this file. The img extension doesn’t say much, and there’s a high chance this a binary file. However, it doesn’t seem so:
$ file X64_G3_3.5.4.RE11.img
X64_G3_3.5.4.RE11.img: POSIX shell script executable (binary data)
$ binwalk X64_G3_3.5.4.RE11.img
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Executable script, shebang: "/bin/sh"
442 0x1BA POSIX tar archive (GNU), owner user name: "s"
Ok, it seems like we have some kind of script and a tar file at the end. Most likely the script is some metadata or basic commands for running the update, while the binary data is the update itself. We can split this file into two ones using dd:
$ dd if=X64_G3_3.5.4.RE11.img of=image.bin skip=441
313019+1 records in
313019+1 records out
160266171 bytes (160 MB, 153 MiB) copied, 1.04405 s, 154 MB/s
$ dd if=X64_G3_3.5.4.RE11.img of=image.tar bs=442 skip=1
363102+1 records in
363102+1 records out
160491521 bytes (160 MB, 153 MiB) copied, 1.18895 s, 135 MB/s
The “script” seems to be both a script and a metadata file:
#!/bin/sh
image_type=firmware
architecture=x86_64
support_models=as61xx as62xx as63xx as64xx as65xx as66xx as31xx as32xx as50xx as51xx as53xx as52xx as70xx as71xx
version=3.5.4.RE11
kernel_skip=21
initramfs_size=14375492
initramfs_skip=576366
builtinfs_size=141508122
builtinfs_skip=576366
body_skip=21
script_line=576366
md5sum=15be0b63f403d990e02369c9db8c8c3d
base_version=3.5.4.RE11
echo ""
echo "$0 [options]"
echo ""
exit 0;
This is interesting. It gives us the offsets on that binary, as well as the version we’re upgrading to. Nice.
The tar file, once extracted, gave us some interesting files:
$ tree
.
├── builtin.tgz
├── builtin.tgz.cksum
├── builtin.tgz.md5sum
├── bzImage
├── bzImage.cksum
├── bzImage.md5sum
├── initramfs
├── initramfs.cksum
└── initramfs.md5sum
0 directories, 9 files
The bzImage is a Linux kernel image. We can extract its string using file and compare to our current kernel version as well. This reveals us that we have an updating coming up, although keeping the same version. Probably just a rebuild, which is fine. Plus, the current kernel is working very well, so I wouldn’t care about it anyway.
$ file bzImage
bzImage: Linux kernel x86 boot executable bzImage, version 4.14.x (root@asustor-build) #1 SMP Mon Feb 1 00:30:19 CST 2021, RO-rootFS, swap_dev 0x4, Normal VGA
$ ssh user@nas uname -a
Linux vault 4.14.x #1 SMP Tue Nov 17 00:29:33 CST 2020 x86_64 GNU/Linux
The initramfs contains a standard Linux initial ramdisk, which is necessary to boot up the OS. The builtin.tgz, once extracted, contained the /usr/builtin folder from the NAS. This directory contains the web interface, as well as some binaries, libraries and all of the CGI stuff. We could, if we want, extract from both these files the whole thing in terms of binaries and libraries to reverse engineer.
Ok, got the image. Now what?
Let’s virtualize it!
Some Googling told me I could use QEMU to spin up the kernel and initramfs quite easily. This is interesting, as it provides a nice opportunity to test it out. And indeed I can:

I’ve managed to successfully boot the main OS, nice!
Since things are never easy, unfortunately some applications start to fail after a few seconds, as it is not able to find the OS disk. This leads to a reboot while the OS is loading, which causes a bunch of daemons to quickly start and stop just before the reboot. And then it starts all again. So, it’s boot looping. The main culprits here are nasmand and stormand.

The good thing about having an actual NAS running is that I can study how it mounts and runs the OS, so I can reproduce the same devices on QEMU. Based on that, I was able to find out that the NAS has 3 RAID setups:
md0, which is a RAID 1 containing Volume 0md1, which is a RAID 5 containing Volume 1 (this is where my data is at)md126, which is a RAID 1 containg Swap (?!)
Personally, I would have used RAID 0 for swap, as it would improve performance. The downside is that, if a disk failed, it could lead to memory corruption. Welp, they should have a reason for doing that.
Anyway, my first guess was md0, as it’s the volume 0. This volume contains the contents of the builtin package, plus some other stuff (mostly configuration). So my guess is that this RAID volume is being set up from that. Ironically, the thing is degraded as it’s missing a disk (?!). Most likely it was due to a disk change in the past, but it’s weird that it didn’t create the partition and fixed it. Go figure.
/dev/md0:
Version : 1.2
Creation Time : Tue Sep 18 18:08:36 2018
Raid Level : raid1
Array Size : 2095104 (2046.34 MiB 2145.39 MB)
Used Dev Size : 2095104 (2046.34 MiB 2145.39 MB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sat Mar 13 20:31:09 2021
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Name : AS3104T-9809:0
UUID : 8ed5a800:57aad661:3e4d213f:a322e33b
Events : 225273
Number Major Minor RaidDevice State
5 8 2 0 active sync /dev/sda2
1 8 18 1 active sync /dev/sdb2
4 8 34 2 active sync /dev/sdc2
6 0 0 6 removed
The weird part is that these disks are mine - I’ve checked both with lsblk and smartctl. Since I didn’t have to install the OS when I bought this NAS, and it came with no disks installed, it must have copied it from somewhere! Where the hell is this firmware? This is what we need to figure out!
Storage comes where we least expect it!
The OS must be loaded from somewhere, but unfortunately there are no other storage devices (that I could find at least). So I decided to look at anything attached to the system, and there’s something funny going on over USB:
# lsusb
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation:2.0 root hub
Bus 001 Device 002: ID 125f:601a A-DATA Technology Co., Ltd.:unknown device 601a
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation:3.0 root hub
That A-DATA device is not mine! There’s no USB device connected to the NAS itself, so it makes no sense to appear on lsusb. Looking up on /sys/class/usb_device I’ve manage to identify it: it’s an IUM01-512MFHL, from A-DATA. This is where things start to get very interesting. You see, this is a storage device! It’s actually a 512MB USB storage device. It’s basically a flash drive, but it connects to USB headers. This review confirms (at least as far as the author knows) that such device is a flash device for storing the firmware. So, what we need to figure out now, is how the hell it works and why it is bootlooping my VM.
Finding the System Disk
Right before everything goes to shit, we get a message stating it can’t mount the system USB disk. The message is coming from nasmand, so let’s take a look at it to figure out what triggers such message. Looking at the disassembled code, we see it tries to mount some partition on /mnt as ext4. This is useful as it narrows down how stuff works.
// (...)
__fd = Is_System_Disk_Available();
if (__fd != 0) {
__sig = Lock_System_Usb_Disk(0);
if ((int)__sig < 0) {
printf("nasmand: can\'t unlock the system disk! (%d)\n",(ulong)__sig);
}
__fd = Mount_File_System(local_24c,"/mnt","ext4",(char *)0x0);
// (...)
Fun fact, Is_System_Disk_Available always returns 1:
undefined8 Is_System_Disk_Available(void)
{
return 1;
}
Anyway, after looking up on Ghidra for a bit, I managed to get the hang of how a few parts of it work. Essentially the NAS tries to get the system disk, mount it, and goes on with anything it needs from there. But then I thought:
Hey, it can’t be this hard. It’s USB, for fuck’s sake.
There’s no way the initram would be able to mount something way too complex without exposing it to the OS. So I’ve decided to do what any normal person would do: find a way of activating the USB device. And there’s something really interesting you can do for that: reset it.
Resetting the USB isn’t really hard on Linux, and there are a few methods around. You can check some of them on this Stack Exchange question. I did the authorized one and got really interesting messages on dmesg. Oh, and by the way:
Don’t try this at home! (unless you are crazy like me and want to see what happens, obviously).
# echo 0 > /sys/class/usb_device/usbdev1.2/device/authorized
# echo 1 > /sys/class/usb_device/usbdev1.2/device/authorized
# dmesg
(...)
[606976.802283] asustor remove disk dev sde
[606976.802355] invalidate_partition: scsi device is invalid
[606978.138314] usb-storage 1-3:1.0: USB Mass Storage device detected
[606978.138854] scsi host4: usb-storage 1-3:1.0
[606978.139101] usb 1-3: authorized to connect
[606979.141570] scsi 4:0:0:0: Direct-Access ADATA IUM01-512MFHL 0100 PQ: 0 ANSI: 0 CCS
[606979.142807] sd 4:0:0:0: Attached scsi generic sg4 type 0
[606979.144514] sd 4:0:0:0: [sde] 1007616 512-byte logical blocks: (516 MB/492 MiB)
[606979.144824] sd 4:0:0:0: [sde] Write Protect is off
[606979.144830] sd 4:0:0:0: [sde] Mode Sense: 43 00 00 00
[606979.145156] sd 4:0:0:0: [sde] No Caching mode page found
[606979.145161] sd 4:0:0:0: [sde] Assuming drive cache: write through
[606979.153829] sde: sde1 sde2 sde3
[606979.470430] sd 4:0:0:0: [sde] Attached SCSI removable disk
AHA! I had from sda to sdd before, as they are my disks. However, sde was always saying “no medium”, stating that it was ejected from the system. Reauthorizing it forced it to redo the handshake, which forced the OS to see it. It clearly has 3 partitions and has a total of a bit over 512MB. Also, it’s exactly the A-DATA device we saw before! Good, let’s carry on from there then!
The System Disk
After extracting the system disk image from the NAS using a simple dd to image it, I’ve started to analyze the damn thing. It has 3 partitions: an EFI one (so modern!) and two data ones. Also, the disk is GPT and not MBR, which is unexpected.
$ fdisk -lu sde.img
Disk sde.img: 492 MiB, 515899392 bytes, 1007616 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 500514A9-1D45-4C66-A3C5-9B0BBECEB783
Device Start End Sectors Size Type
sde.img1 2048 6143 4096 2M EFI System
sde.img2 6144 505855 499712 244M Microsoft basic data
sde.img3 505856 1005567 499712 244M Microsoft basic data
Mounting each of those partitions 244MB partitions only gave me copies of the current firmware, which is even more weird. So… it basically copies the firmware to any disk it has? That doesn’t make much sense. Or maybe it loads to RAM? Who knows.
$ sudo mount -t ext4 -o loop,offset=3145728 sde.img /mnt
$ ls -la /mnt
total 156317
drwxr-xr-x 3 root root 1024 Dec 13 12:30 .
drwxr-xr-x 19 root root 4096 Feb 27 13:59 ..
-rw-r--r-- 1 root root 141080771 Dec 13 12:30 builtin.tgz
-rw-r--r-- 1 root root 83 Dec 13 12:30 builtin.tgz.cksum
-rw-r--r-- 1 root root 97 Dec 13 12:30 builtin.tgz.md5sum
-rw-r--r-- 1 root root 4590496 Dec 13 12:30 bzImage
-rw-r--r-- 1 root root 78 Dec 13 12:30 bzImage.cksum
-rw-r--r-- 1 root root 93 Dec 13 12:30 bzImage.md5sum
-rw-r--r-- 1 root root 14371324 Dec 13 12:30 initramfs
-rw-r--r-- 1 root root 81 Dec 13 12:30 initramfs.cksum
-rw-r--r-- 1 root root 95 Dec 13 12:30 initramfs.md5sum
drwx------ 2 root root 12288 Jun 22 2016 lost+found
$ sudo umount /mnt
$ sudo mount -t ext4 -o loop,offset=258998272 sde.img /mnt
$ ls -la /mnt
total 156318
drwxr-xr-x 3 root root 1024 Dec 13 12:30 .
drwxr-xr-x 19 root root 4096 Feb 27 13:59 ..
-rw-r--r-- 1 root root 141080771 Dec 13 12:30 builtin.tgz
-rw-r--r-- 1 root root 83 Dec 13 12:30 builtin.tgz.cksum
-rw-r--r-- 1 root root 97 Dec 13 12:30 builtin.tgz.md5sum
-rw-r--r-- 1 root root 4590496 Dec 13 12:30 bzImage
-rw-r--r-- 1 root root 78 Dec 13 12:30 bzImage.cksum
-rw-r--r-- 1 root root 93 Dec 13 12:30 bzImage.md5sum
-rw-r--r-- 1 root root 14371324 Dec 13 12:30 initramfs
-rw-r--r-- 1 root root 81 Dec 13 12:30 initramfs.cksum
-rw-r--r-- 1 root root 95 Dec 13 12:30 initramfs.md5sum
drwx------ 2 root root 12288 Jun 22 2016 lost+found
$ sudo umount /mnt
Also, if you mount the EFI partition, you get cool and very useful stuff, such as the grub.cfg. This indicates that it might, somehow, use GRUB (even though the command line might indicate LILO? (we’ll talk about it later)). But, nevertheless, useful and important stuff:
$ tree /mnt
/mnt
├── boot
│ └── grub
│ ├── grub.cfg
│ ├── grubenv
│ └── x86_64-efi
│ ├── efi_gop.mod
│ ├── font.mod
│ ├── serial.mod
│ ├── terminal.mod
│ ├── terminfo.mod
│ ├── video_bochs.mod
│ ├── video_cirrus.mod
│ ├── video_fb.mod
│ └── video.mod
└── EFI
└── Boot
└── bootx64.efi
5 directories, 12 files
$ cat /mnt/boot/grub/grub.cfg
#
# DO NOT EDIT THIS FILE
#
# It is automatically generated by grub-mkconfig using templates
# from /etc/grub.d and settings from /etc/default/grub
#
insmod efi_gop
insmod video
insmod video_bochs
insmod video_cirrus
insmod video_fb
insmod serial
serial --unit=0 --speed=115200 --word=8 --parity=no --stop=1
terminal_input serial
terminal_output serial
set timeout=2
menuentry 'ASUSTOR image' {
linux (hd0,gpt2)/bzImage console=ttyS0,115200n8
initrd (hd0,gpt2)/initramfs
}
menuentry 'ASUSTOR safe image' {
linux (hd0,gpt3)/bzImage console=ttyS0,115200n8
initrd (hd0,gpt3)/initramfs
}
Anyway, I was thinking about how to approach this and a thought crossed my mind: hey, let’s attach this disk image to the USB on the VM. Since the code is looking for an USB device, let’s give it one. We almost got there on the first try: the kernel found it, but nasmand and stormand did not.
qemu-system-x86_64 \
-kernel bzImage \
-initrd initramfs \
-m 1G \
-hda ../disk1.img \
-hdb ../disk2.img \
-drive if=none,id=sde,format=raw,file=../sde.img \
-device nec-usb-xhci,id=xhci \
-device usb-storage,bus=xhci.0,drive=sde
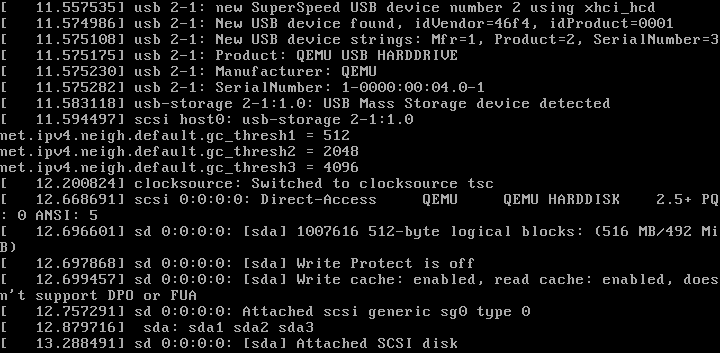
Damn it! We got some progress at least! So close, and yet so far!
How the hell does this thing work?
After a few good hours on nasmand, I still couldn’t figure out what was going on. The disassembled code is messy and takes a while to understand, but I still couldn’t find where it was loading the information of what is the system disk from. So I turned my eyes to the second process that kills the system: stormand.
The Storage Manager Daemon, or stormand, is the one that triggers a system reboot after not finding the system disk. There’s a specific message that I looked for (“Try to get the booting device!”) in the code, which lead me to a big-ass function. There, the system disk would be locked (just like nasmand), but then it would be probed.
// (...)
bVar16 = 0;
uVar6 = Get_Tick_Count();
Lock_System_Usb_Disk(0);
iVar1 = Lookup_Nas_Info(local_e8);
if (-1 < iVar1) {
if ((local_a4[0] == '\0') || (uVar15 = local_9c[0] == '\0', (bool)uVar15)) {
lVar7 = 8;
puVar11 = &local_228;
while (lVar7 != 0) {
lVar7 = lVar7 + -1;
*(undefined4 *)puVar11 = 0;
puVar11 = (undefined8 *)((long)puVar11 + ((ulong)bVar16 * -2 + 1) * 4);
}
uVar9 = 0;
do {
uVar2 = Probe_Booting_Device(0x20,(char *)&local_228,0x20,(char *)local_68);
uVar8 = (uint)uVar9;
if (-1 < (int)uVar2) {
printf("stormand: The system is booting from [%s] with filesystem type [%s]... (%d)\n",
&local_228,local_68,uVar9);
break;
}
uVar8 = uVar8 + 1;
printf("stormand: Try to get the booting device! (%d, %d)\n",(ulong)uVar2,uVar9);
Sleep_MSec(500);
uVar9 = (ulong)uVar8;
} while (uVar8 != 5);
// (...)
So the first thing I wanted to know is exactly what this function returns on real hardware. This is easy, we just need to call it! Calling it returned exactly what I expected, ironically.
#include <stdio.h>
#include <stdlib.h>
extern int _Z20Probe_Booting_DeviceiPciS_(int param_1,char *param_2,int param_3,char *param_4);
int main() {
char param1[256] = {0};
char param2[256] = {0};
int retval = _Z20Probe_Booting_DeviceiPciS_(0x20, param1, 0x20, param2);
printf("%s, %s, %d\n", param1, param2, retval);
return 0;
}
# ./test3
/dev/sde2, ext4, 0
The reason why I expected sde2 is easy: the boot command line. If we look at the boot command line on the NAS (located at /proc/cmdline), we can see it looks for partition 2 on disk 0:
BOOT_IMAGE=(hd0,gpt2)/bzImage console=ttyS0,115200n8 bootpart=2 uuid=84404f12-4e4c-44d2-b384-4b6c2752e1ba
So, returning sde2 is expected. And, before you ask, no, nothing matches BOOT_IMAGE on the libraries or binaries, unfortunately. This seems to be related to LILO, which uses this parameter to be able to boot the OS. Since we’re booting it using QEMU, I believe we can ignore this for now. Also, providing bootpart or uuid have no effect whatsoever, even though these strings are present inside some libraries. Anyway, let’s carry on with studying the code.
The Probe_Booting_Device function starts by probing the PCH, and then calling a second (unnamed) function. Probing the PCH is the part that scares me a bit as we’re now emulating one - oops.
/* Probe_Booting_Device(int, char*, int, char*) */
undefined8 Probe_Booting_Device(int param_1,char *param_2,int param_3,char *param_4)
{
undefined8 uVar1;
int local_1c;
if ((((param_2 == (char *)0x0) || (param_1 < 10)) || (param_4 == (char *)0x0)) || (param_3 < 4)) {
uVar1 = 0xffffffea;
}
else {
uVar1 = Probe_Nas_Pch(&local_1c);
if (-1 < (int)uVar1) {
uVar1 = FUN_00129b80(param_1,param_2);
if ((int)uVar1 < 0) {
uVar1 = 0xffffffed;
}
else {
*(undefined4 *)param_4 = 0x34747865; // "ext4", just reversed.
param_4[4] = '\0';
}
}
}
return uVar1;
}
Nevertheless, based on the execution flow of stormand, we know that this function is returning a negative value on QEMU - more specifically, -42. This is important, as this means the FUN_00129b80 is never called: 0xffffffed is -19. This is important, as this means the -42 is a result coming straight from Probe_Nas_Pch. And indeed it makes sense: that function will scan for PCI devices and find a specific one.
/* Probe_Nas_Pch(int&) */
int Probe_Nas_Pch(int *param_1)
{
int iVar1;
int iVar2;
int retval;
int *piVar3;
_T_PCI_DEVICE_RECORD_ pci_record [780];
int local_3c [3];
local_3c[0] = 0x300;
iVar1 = Scan_Pci_Device(local_3c,pci_record);
if (iVar1 < 1) {
retval = -0x104;
}
else {
retval = -0x2a;
if (-1 < DAT_0039a440) {
retval = 0;
piVar3 = &DAT_0039a468;
do {
iVar2 = Find_Pci_Device((_T_PCI_DEVICE_ID_ *)(&DAT_0039a458 + (long)retval * 0x28),iVar1,
pci_record);
if (0 < iVar2) {
*param_1 = (&DAT_0039a440)[(long)retval * 10];
return 0;
}
retval = retval + 1;
iVar2 = *piVar3;
piVar3 = piVar3 + 10;
} while (-1 < iVar2);
retval = -0x2a;
}
}
return retval;
}
On the real hardware, this returns 3, meaning it completes the flow correctly. On emulated hardware, it’s returning -42, which is -0x2a we have twice at the code. This means the first call (Scan_Pci_Device) is successful, returning a positive number. This seems to be a PCI device count, and QEMU has PCI devices, so this is fine. Following up on the code, it sets the return value to -42, and then check a specific memory address, which has 00 00 00 00 as it’s value during the code analysis. I checked it on GDB during runtime and indeed, it’s zeroed out.
If we carry on with the execution and follow the path using GDB, we can see it plays with address 0039a458. Ironically, this address contains 0x80860601: 8086 is the vendor ID for Intel, and 0601 is a PCI device class (called “ISA bridge” on lspci). Taking a look at the memory area around it, we see other possible PCI device IDs, which leads to believe we’re looking for an Intel PCH.
(gdb) x/32x 0x7ffff7ddb440
0x7ffff7ddb440: 0x00000000 0x00000210 0xf7bc75d1 0x00007fff
0x7ffff7ddb450: 0x00000056 0x00000000 0x80860601 0x3a163a16
0x7ffff7ddb460: 0xf7b6a380 0x00007fff 0x00000001 0x00000330
0x7ffff7ddb470: 0xf7bc75d1 0x00007fff 0x00000054 0x00000000
0x7ffff7ddb480: 0x80860601 0x72708c56 0xf7b69b20 0x00007fff
0x7ffff7ddb490: 0x00000002 0x00000130 0xf7bc75d1 0x00007fff
0x7ffff7ddb4a0: 0x00000056 0x00000000 0x80860601 0x72700f1c
0x7ffff7ddb4b0: 0xf7b694b0 0x00007fff 0x00000003 0x00000130
Now how exactly this device works on other architectures is a whole mistery for me. They probably have different libraries in such cases.
This is getting way too deep.
Trick or patch?
Ok, so here’s our challenge now: we need to make the code continue looking for the boot device regardless of the PCH, or at least avoid rebooting. There are a few ways we can do this, in order of the simplest to the hardest (IMHO).
- Mess with QEMU or even a different virtualization tool to get a full Intel PCH working. Messing with QEMU is tricky, but using a different virtualization tool is even tricker. Setting this up on VirtualBox or even VMware might take a few hours as we need a proper bootloader as well (cof cof GRUB cof cof).
- Replace
stormandandnasmandwith dummy binaries. Since these are daemons, this could be done. However, replacing them could kill some OS functionality, but at least, by being still present, the OS can continue to boot. - Patch the code to avoid the reboot call. This would avoid rebooting the OS. It might get stuck, kill or crash some stuff, but it’s something that could be done.
- Patch the code around the PCH check so that we can continue the boot process regardless of the PCH. This has the an issue: if it’s used anywhere else, we have no idea what might happen (probably segmentation faults).
- Add a dummy PCI device to QEMU matching the vendor, product and class IDs, just so the code continue. Since the PCH is not used in the boot code, this would work. Just like the previous one, if it’s used anywhere else, we might be screwed though.
Let’s try them - or some of them!
Attempt 1: running on VMware and VirtualBox
I gotta be honest, I tried for many hours to get VMware or even VirtualBox to boot the image, but unfortunately I got nowhere. I learned a lot about GRUB though. On VMware, using a copy of the system disk attached over SATA and another one over USB, I managed to get to boot the OS, but unfortunately I still got stuck on the stormand trying to reboot the OS. Same error code, -42. I even managed to get a shell and killed it, but it was soon restarted. Removing the binary helped a bit, but not by much.
This was, nevertheless, useful. I now know more or less how to boot the OS when booting on a VM. This also gave me experience on GRUB, which would be very useful if we want to boot the system on anything else QEMU. Not that QEMU is bad, it’s just very slow for me. That’s my fault though: I’m running it inside a VM and I don’t have anything to improve its virtualization there. Welp.
Attempt 2: replacing the demons.. I mean, daemons!
We got the daemons on initramfs, so we need to unpack it, replace the binaries, repack and boot. This isn’t that hard, and the commands for doing this process are described on this page, as well as this one. The main downside on doing this is that we won’t be running the original firmware image, but a modded one. But at least for an initial boot just for fun, or even for a test/build environment, this could work.
Anyway, that’s what we did!
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
printf("argc = %d\n", argc);
for (int i = 0; i < argc; i++) {
printf(" %d: %s\n", i, argv[i]);
}
return 0;
}
I even made a script for patching the thing easier, as it’s faster whenever I needed to try multiple combinations. I obviously needed to try many, many combinations. Compressing the damn initramfs is a mess.
#!/bin/bash -e
OUTPUT=../initramfs.patched
TEMPFOLDER=./tmp-initramfs-patch
rm -rf $OUTPUT $TEMPFOLDER
mkdir -p $TEMPFOLDER
cd $TEMPFOLDER
echo ">> Extracting"
xz -dc < ../initramfs | cpio -idmv
echo ">> Patching"
cp ../dummydaemon ./usr/sbin/nasmand
cp ../dummydaemon ./usr/sbin/stormand
echo ">> Compressing"
find . 2>/dev/null | cpio --create --format='newc' | xz --check=crc32 --format=xz --lzma2=dict=64MiB > $OUTPUT
echo ">> Done: initramfs.patched has been created"
cd ..
rm -rf $TEMPFOLDER
The question is: did it work? And yes it did! Well, mostly!
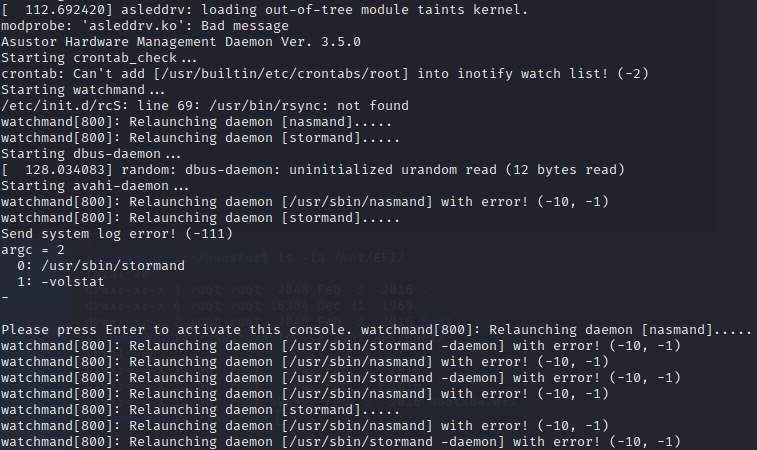
It seems nasmand and stormand are expected to keep running, otherwise the watchmand will be pissed off. We can kill it off as well, just to see what happens.
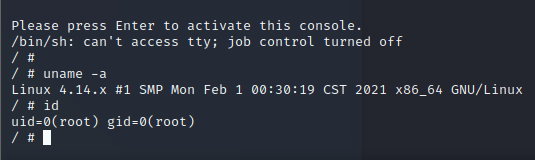
Well, I’m in.
Playing with it
Playing with the damn image is a bit weird on QEMU, but it’s not that hard. But honestly, now the “hack” is pretty much. I mean, I can run the (modded) firmware on QEMU, and since we disabled the daemons that forced the system to reboot without the USB system disk, we can actually boot this off a (normal) disk. This means we can (eventually) migrate this to VMware or VirtualBox. This would be quite better, as it’s way easier to work with.
Nevertheless, I managed get to “network” working after a while - in the end I just did a port forward as it’s a pain in the ass to configure it. All I wanted to see was this:
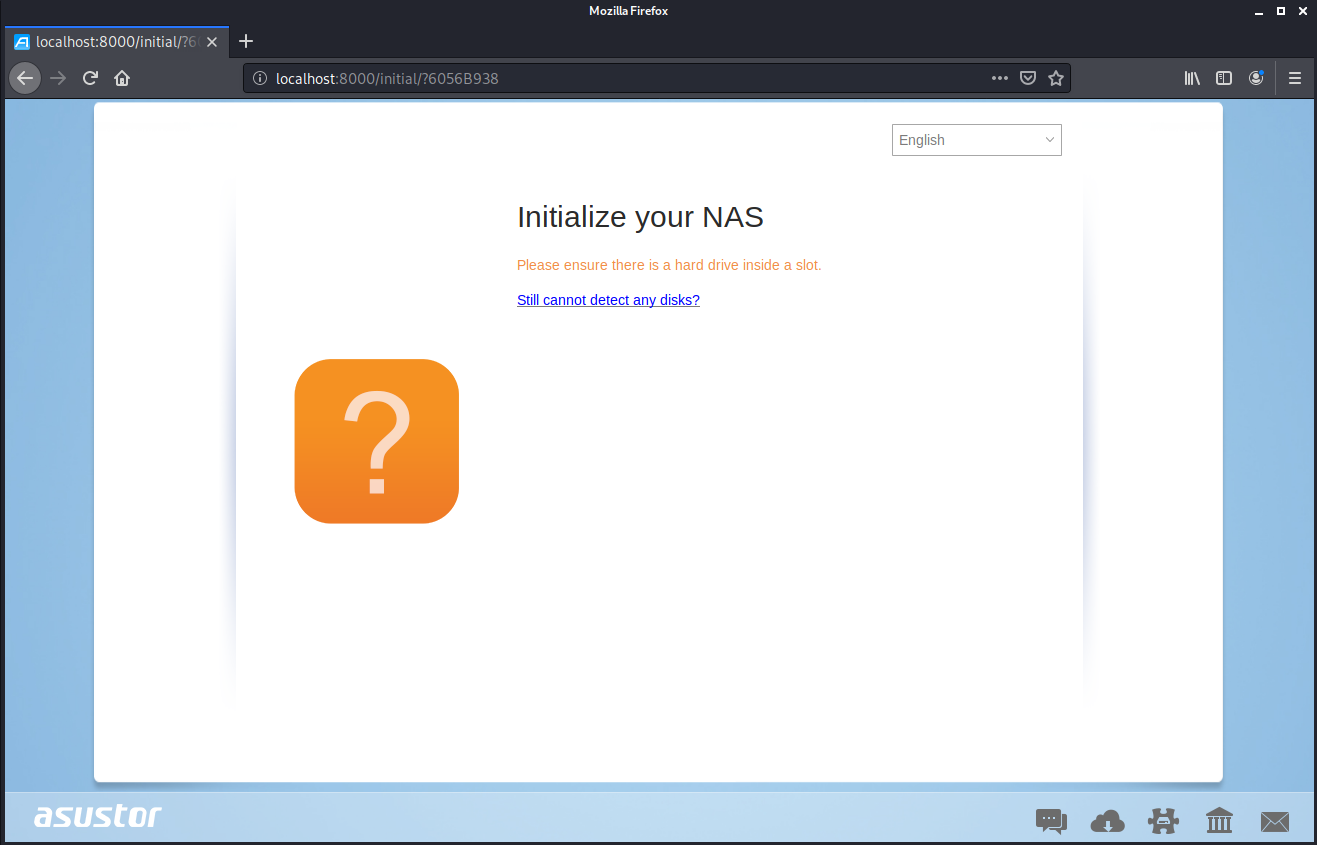
YES!

But, this is where we stop - I had to draw the line somewhere, sorry. In the next part we’ll hopefully figure out why it won’t find any disks and maybe get it out of QEMU and into VMware (foreshadowing). We’ll see how it goes.
Nevertheless, what we got so far is a huge success: we managed to get the firmware image, deconstruct it, hack it and run the damn thing into a VM! This has been an interesting challenge regardless of the results we get in the next weeks, and I hope you enjoy it as well.
Cya!